Two days at ExCeL. Hundreds of vendors. Thousands of conversations. And yet, walking away from …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Two days at ExCeL. Hundreds of vendors. Thousands of conversations. And yet, walking away from …

It’s Black Friday morning. Your stores are packed with customers. Credit card in hand, a …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

The retailer is charting its next chapter with retail technology modernization to power inspired omnichannel …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …
Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

Setting up SymmetricDS for clustering can be done a few different ways and can help solve a few different use cases. This blog will address a few of the common setups we see while utilizing clustering.
In general clustering in SymmetricDS is achieved when multiple installations of SymmetricDS access the same database. This might be for high availability, performance or even both. This behavior though is not turned on by default and would result in a variety of errors if multiple nodes were configured to access the same database through the same connection url. The various jobs that run within SymmetricDS would end up running against the same set of runtime tables and cause collisions and conflicts while fighting for access. To solve this you must tell SymmetricDS that a node should run in clustered mode a locking table will be used to prevent nodes in the same cluster from running on top of each other.
The simplest setup for clustering involves setting the following parameter on all engines that are clustered (set on the engine file directly in the engines folder of your SymmetricDS installation).
cluster.lock.enabled=true
In addition to this property being added to the engine file all other initial properties should match. So the easiest setup for a cluster is to copy the engine file from one installation to another and add the cluster enabled property. However if you have a db.password that is encrypted (starts with enc:) you will also need to copy over the security folder files from the original installation to the new one as well so that the database password can be decrypted.
For more advanced setup and configuration see the clustering section in the documentation.
https://downloads.jumpmind.com/symmetricds/doc/3.12/html/user-guide.html#_clustering
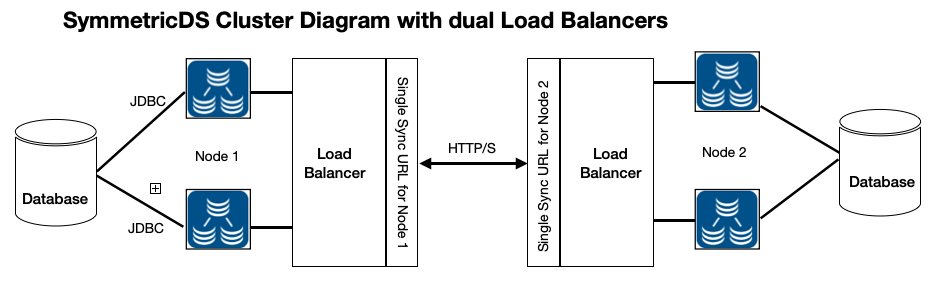
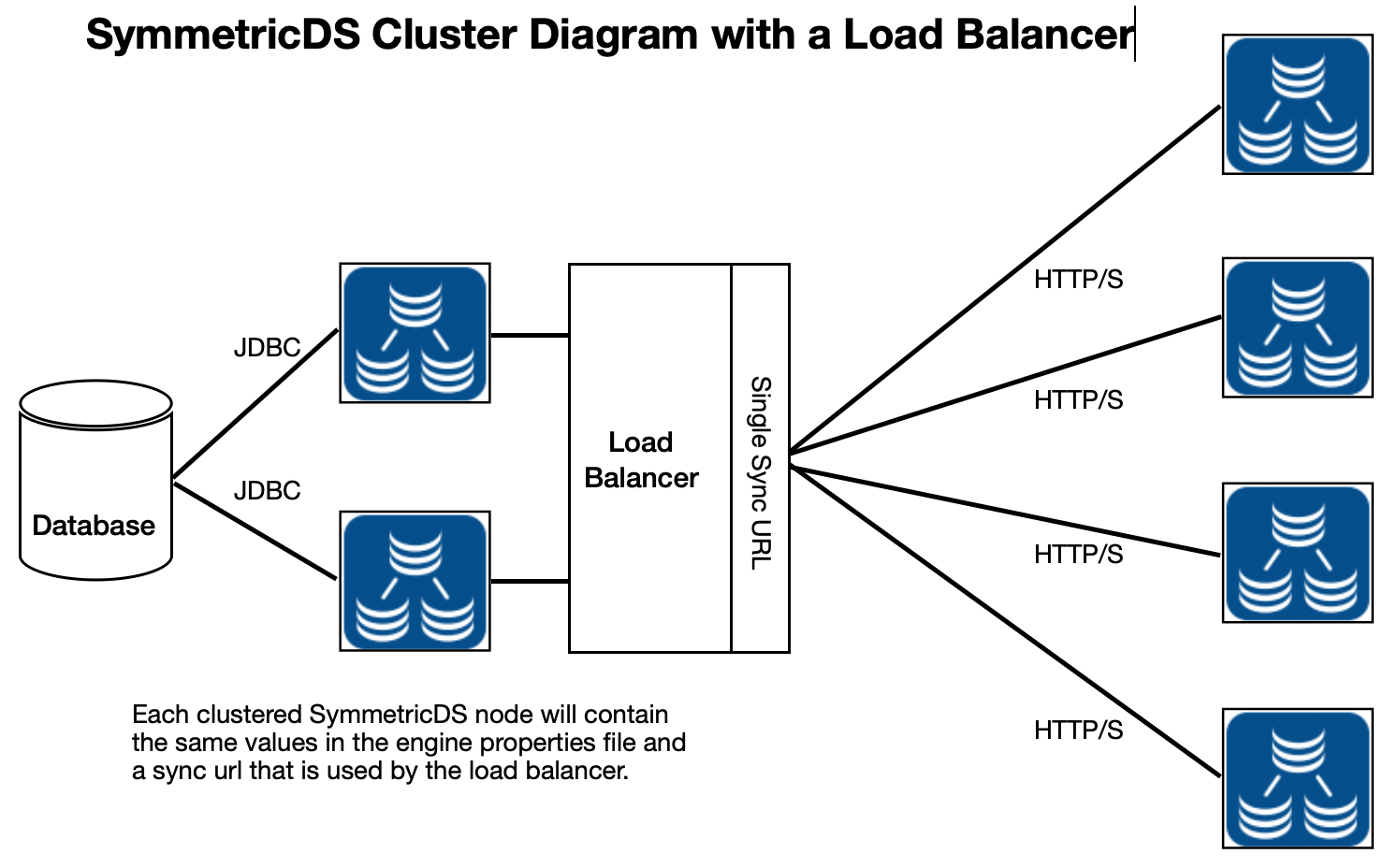
The most common use case that involves SymmetricDS clustering is through a load balancer to help support multiple client nodes. This helps in scaling the central database for replicating to hundreds or even thousands of client nodes. It can also serve as a high availability use case so that replication to a central node continues even if a central SymmetricDS node goes down.
The key to this setup is that all the nodes behind the load balancer use the same sync url. This sync url is the end point of the load balancer and the url that all client nodes will communicate on to access the central node. So be sure in this setup that the sync url is the same for all the nodes behind the load balancer.
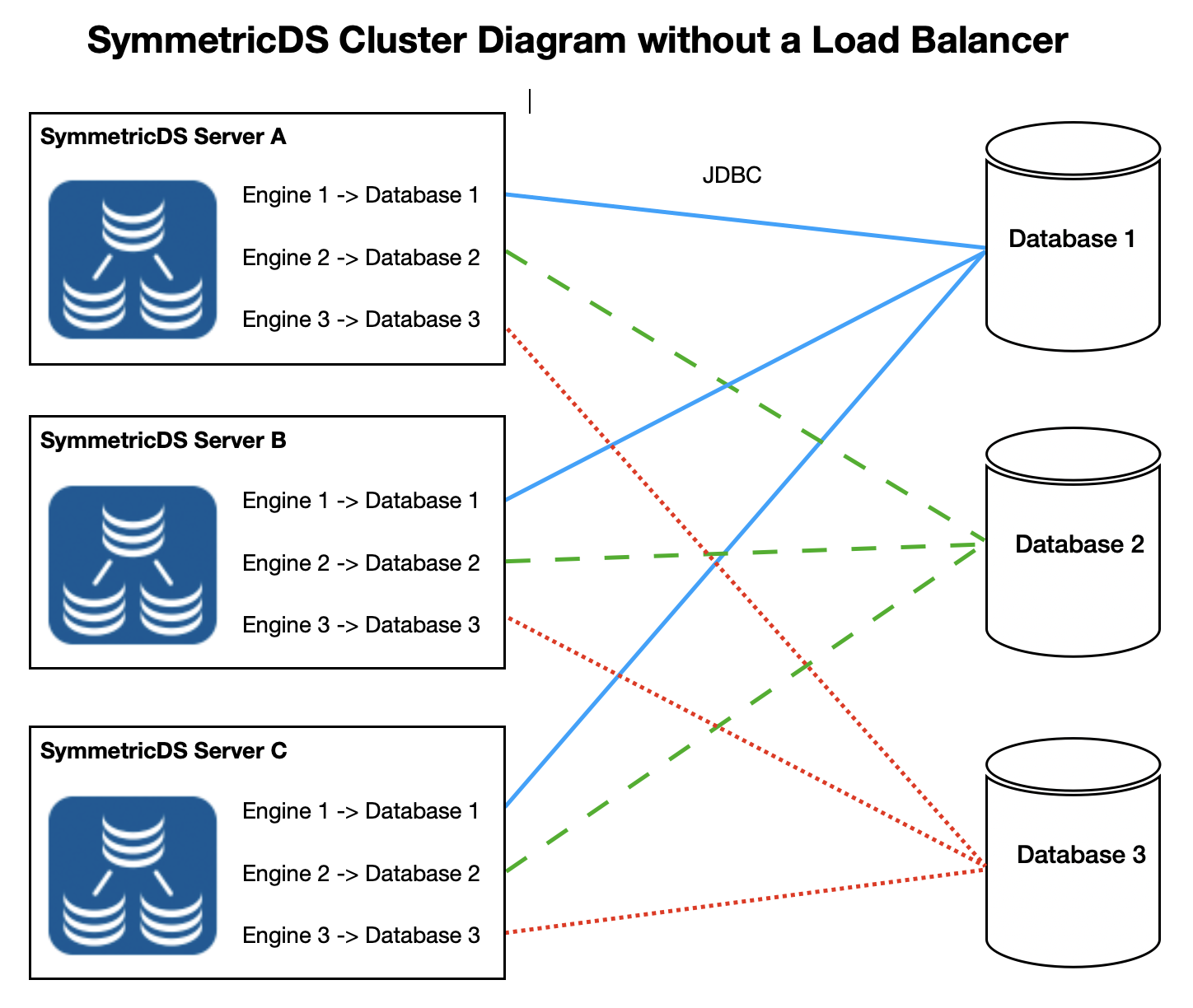
If all the databases being replicated are on the same network (not over a WAN) then all nodes/engines can run under a single installation of SymmetricDS (multi-homed). If this is the case you can cluster more installations of SymmetricDS without a load balancer. This provides both high availability if a server fails as well as some distribution of the workload.
The key to this setup is that all of the engines sync.url and registration.url values should use a host name of localhost. This ensures that a request between node 1 and node 2 on server A will remain on server A and will not need to be sent through a load balancer.
The basic clustering principles still apply though. Cluster enabled parameter must be set to true in all engine property files and the engine files that represent the same node must all match. So engine 1 properties file will be identical in all their SymmetricDS servers below. This also means than the security folder from the original installation should also be used for all future clustered additions so that the db.password can be decrypted.
It is also possible to use two load balancers or two load balancer endpoints as well in a clustered setup. Below is an example of a simple 2 node bidirectional replication setup that contains a load balancer on each side. This would provide high availability and scaling for two high traffic critical nodes. Again all other principles apply with setting the cluster enabled etc. This time the sync.url for the two node 1 engines will match and be that of the load balancer on the left. A similar setup will occur by providing the load balancer on the rights endpoint as the sync.url for the node 2 engine files.