Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
The new release of SymmetricDS Pro 3.16 data replication software simplifies setup, improves performance, and includes additional support for cloud and security. This release will help you:
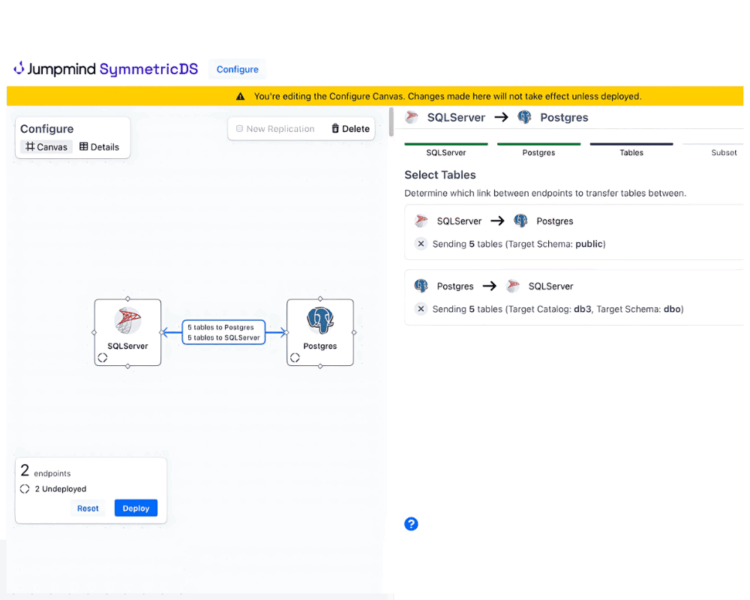
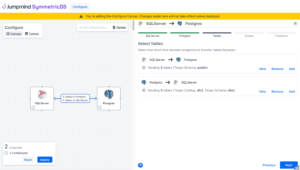
The Configure tab now features a Canvas, replacing the Design tab with a new approach to configuring replication. Common replication scenarios are now simplified to setup using a visual canvas of connected nodes and the tables being replicated. Transforms are now created by drawing lines between tables and columns, even showing implied mappings as dashed lines. Changes are applied with a deployment wizard that collects final settings, creates engines, and prepares replication. The familiar original screens are still available with advanced settings.
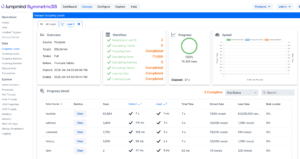
Scaling the number of threads used for an initial data load is now automatic, with parameters to control the total number of threads available. Tables load in parallel, giving each thread exclusive access to its table to load with native bulk loaders and direct access paths. The Loads screen was improved to consolidate the view of tables and includes more statistics and feedback on progress.
In addition to supporting triggers and log mining, the option of time-based change data capture is now available. For a third-party database with read-only access or databases where other options are not available, time-based capture can periodically retrieve changes based on timestamps. The deployment wizard will automatically select candidate columns based on name and data type, which the user can adjust. If no appropriate columns exist, the deployment will setup overnight initial loads instead.
Bulk extract using native tools is now supported for SQL-Server and SAP (Sybase) ASE using the bcp bulk copy utility. Bulk loading using the bcp bulk copy utility is now supported on SAP ASE in addition to SQL-Server. The setup program and node wizard now perform automatic installation and configuration of native bulk loaders for SQL-Server and Oracle. The PostgreSQL bulk loader was improved to create unlogged tables and use binary mode copy, resulting in a 30% performance improvement.
Internal runtime tables now use their own thread queue that is separate and replicates independently. The system caches the list of ready queues to reduce queries and make efficient use of threads and memory. When replicating between nodes that are co-hosted, the source staging area is used by the target node to avoid a copy operation for faster local transfer. Routing of changes into batches now defaults to multi-threaded mode with a thread per channel.
File sync now supports Azure Blob Storage and Simple Storage Service (S3) buckets as both a source or target of files. Consolidate multiple on-premise locations to a scalable object storage in the cloud that is centrally accessible. Store and access unstructured data at scale, build cloud-native applications, or optimize workloads for data lakes.
Web console users can now authenticate with single sign-on (SSO) using the OAuth2 and OpenID Connect (OIDC), in addition to options for LDAP, Active Directory, and SAML. A role mapping feature allows the user’s role from the identity provider to be mapped into a web console role.
Migrate data, send partial data loads, and replicate changes to Exasol database. Exasol is an in-memory relational database built for high performance analytics. Even though it was designed to run in memory, it persists to disk following ACID rules and follows SQL query standards. Support for Exasol makes it a compelling data migration target for building a data warehouse.



