I just got back from Shoptalk in Las Vegas, and this year’s show hit differently …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
I just got back from Shoptalk in Las Vegas, and this year’s show hit differently …

When I joined Jumpmind, one of the first things that struck me was how consistently …

Physical retail is back as a growth engine; RSR research shows that 85% of retailers …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

The retailer is charting its next chapter with retail technology modernization to power inspired omnichannel …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …

LONDON, March 17, 2026 — Jumpmind, a leading provider of innovative retail technology solutions, today …

Last week, I had the opportunity to be at EuroShop 2026 in Düsseldorf, Germany, the …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

If the source data to be replicated resides in a read-only (select only) database, common replication approaches like log based or trigger based are not an option. Through some additional configuration and a few prerequisites on the source database SymmetricDS can still be used for replication in a time based approach.
Time based replication is when data is selected out of the source directly and used to replicate to the target(s). Unlike log based or trigger based where there is a precise capture of each change. Time based will require some assumptions or additional overhead to determine the changes. If for example, the source table(s) have a column that indicates the last update times this can be used to obtain changes (although not deletes, discussed below). Another approach might be to select all data out of the source and compare it to the target. Although this seems more precise it might not be feasible on larger data sets or databases that incur a lot of consistent changes.
If you are limited though to read-only access to the source data then the time based approach might be your best and only option to replicate changes to a target database.
First, we need to identify the limitations of time based replication to determine if this approach will work with your source database.
Does it contain a last updated column?
Do the tables to be replicated contain a column that has an accurate date-time of the last time a row was modified? If not it might not be possible to determine the changes on this source database without a full data comparison against source and target. For this article, we will only focus on the cases where such a last updated column exists on the source tables.
Do deletes matter?
Deletes will not be captured in this approach unless it is a soft delete where a column (maybe named “deleted”) indicates the row is no longer active. In this case, it is just an update to a column to represent a delete and will replicate. If you need to fully replicate deletes again this would be outside the scope of this article and a full comparison would need to be done against the source and target.
Prerequisites
Setting up tables
* There will be two table triggers configured in SymmetricDS for each table. One set is to be used for a full initial load to send all data in the source tables. The second will use an initial load select to only select data based on a Time based interval.
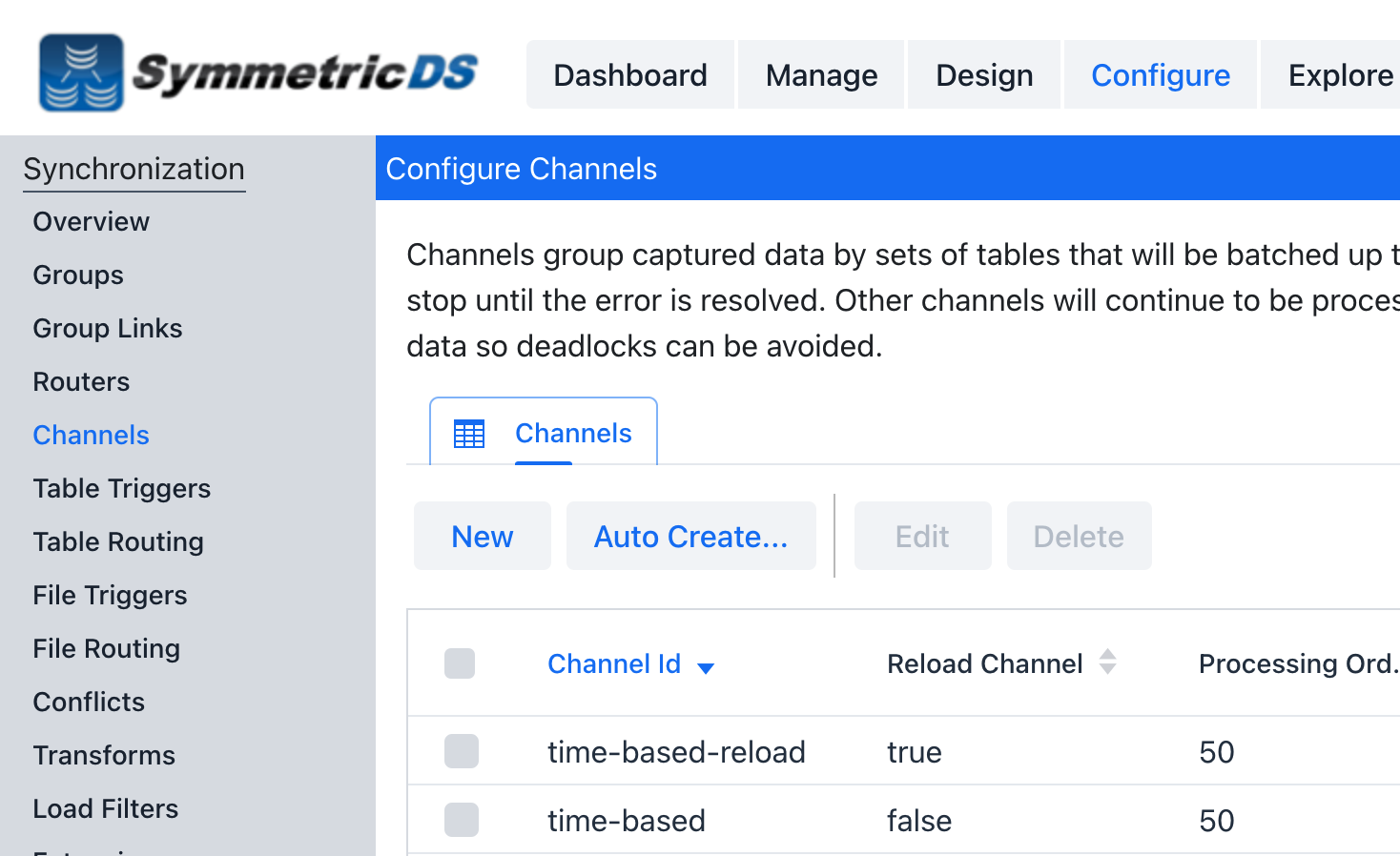
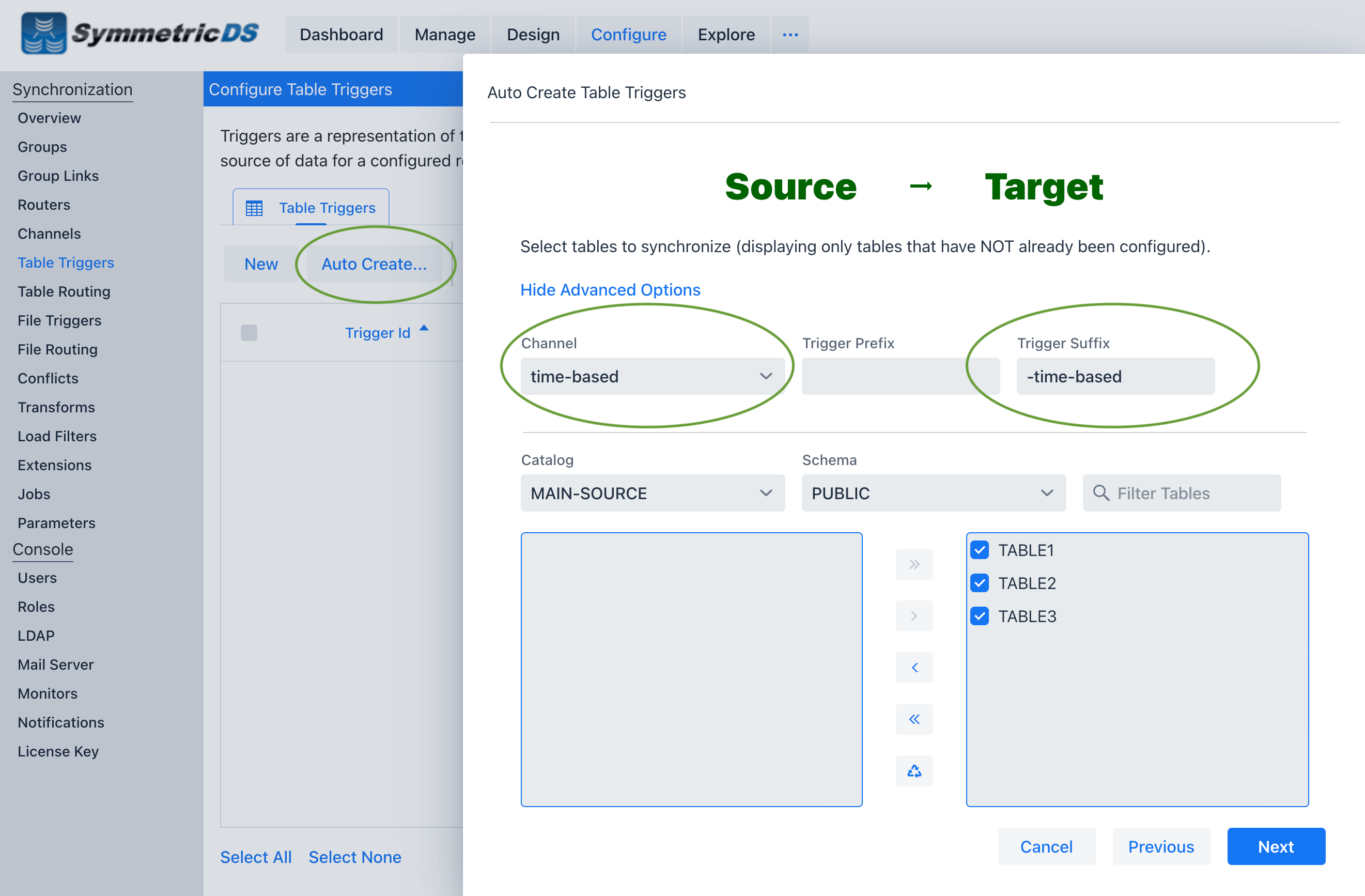
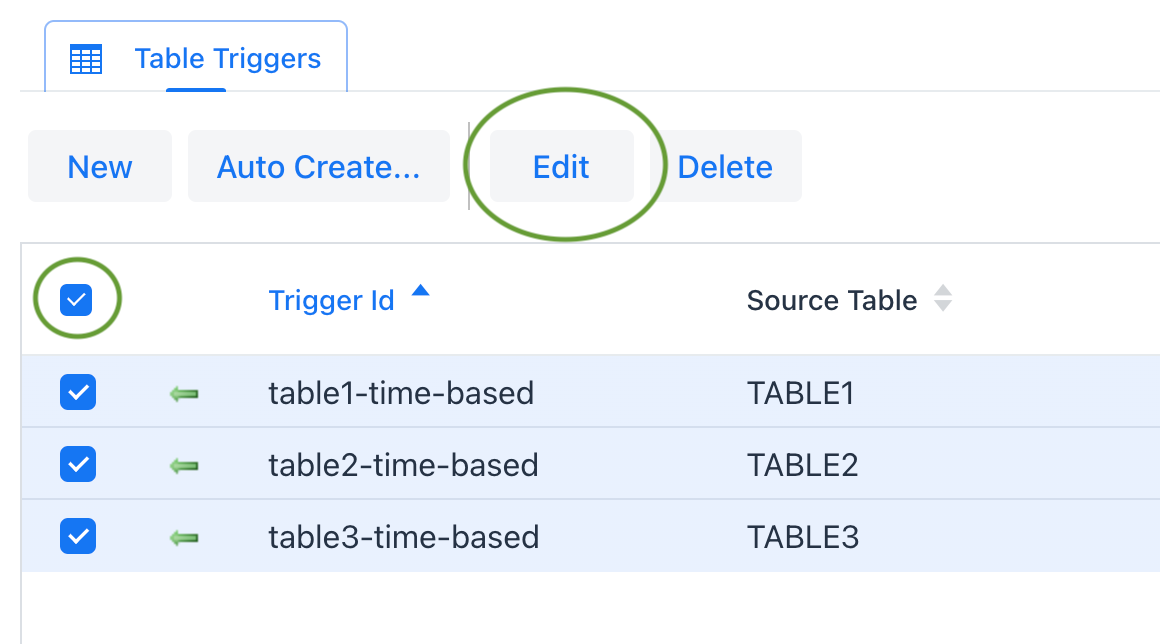
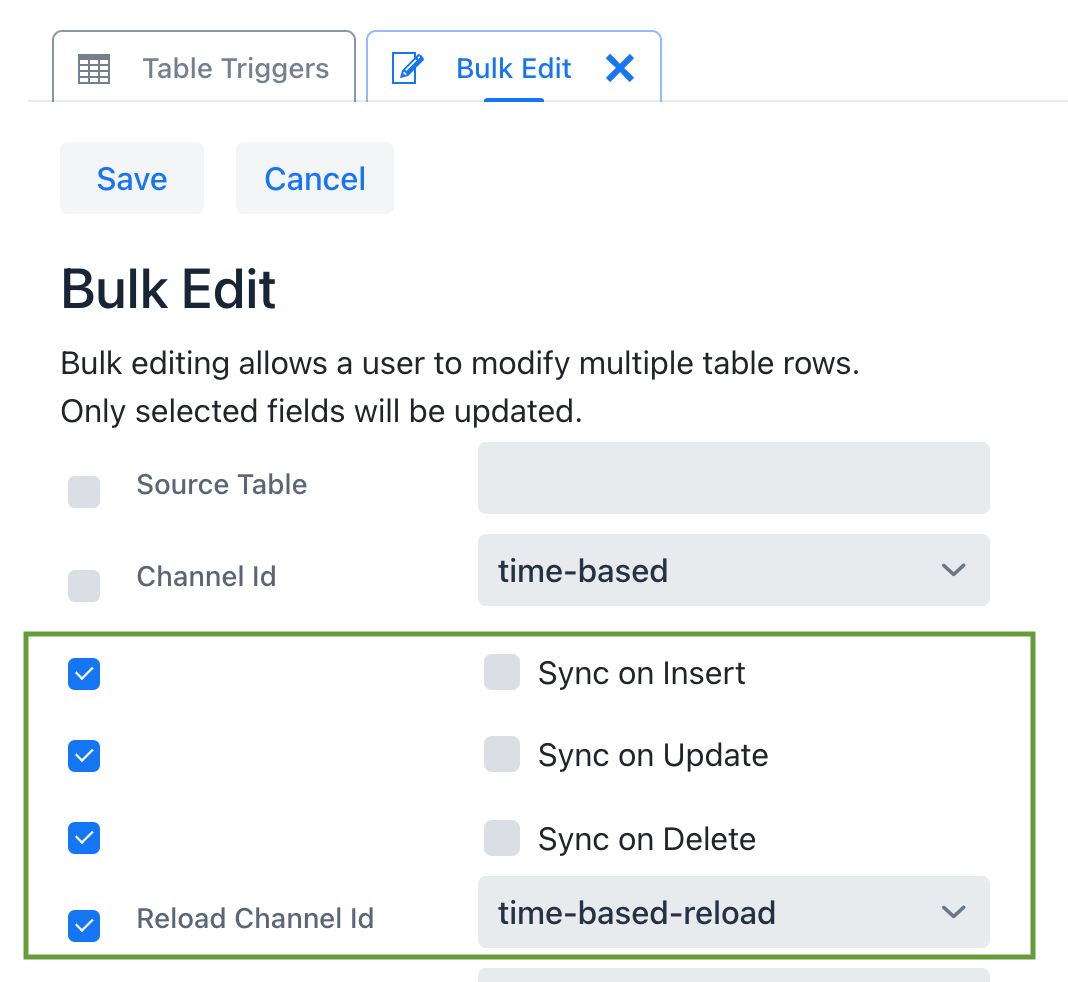
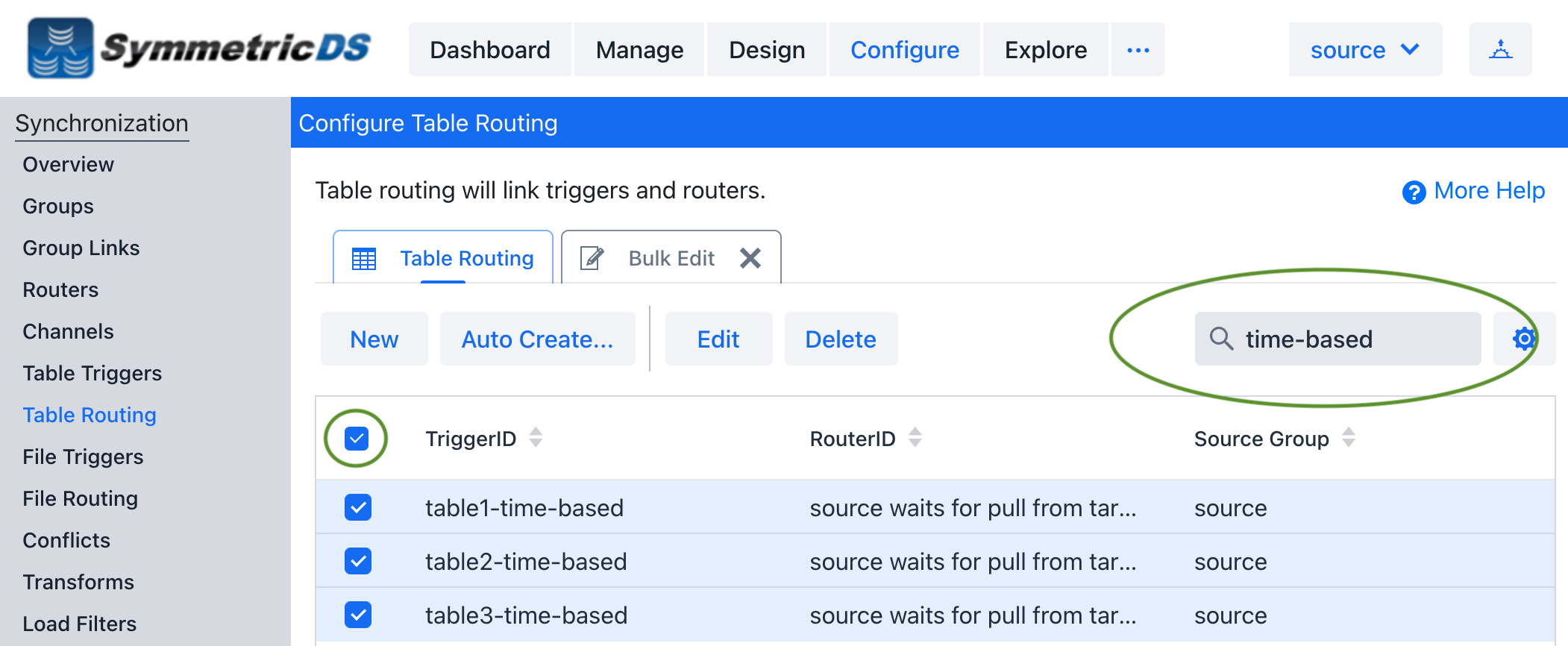
Table 1 – Below is a list of examples how to go back 1 minute using a where clause on several common dialects
| Oracle | last_updated_time >= (sysdate-(1/1440)) |
| MSSQL | last_updated_time > DATEADD(MINUTE, -1, GETDATE()) |
| MySQL | last_updated_time >= DATE_SUB(NOW(),INTERVAL 1 MINUTE); |
| Postgres | last_updated_time >= (NOW() – INTERVAL ‘1 minute’ ) |
| H2 | last_updated_time > DATEADD(‘MINUTE’,-1, CURRENT_DATE) |
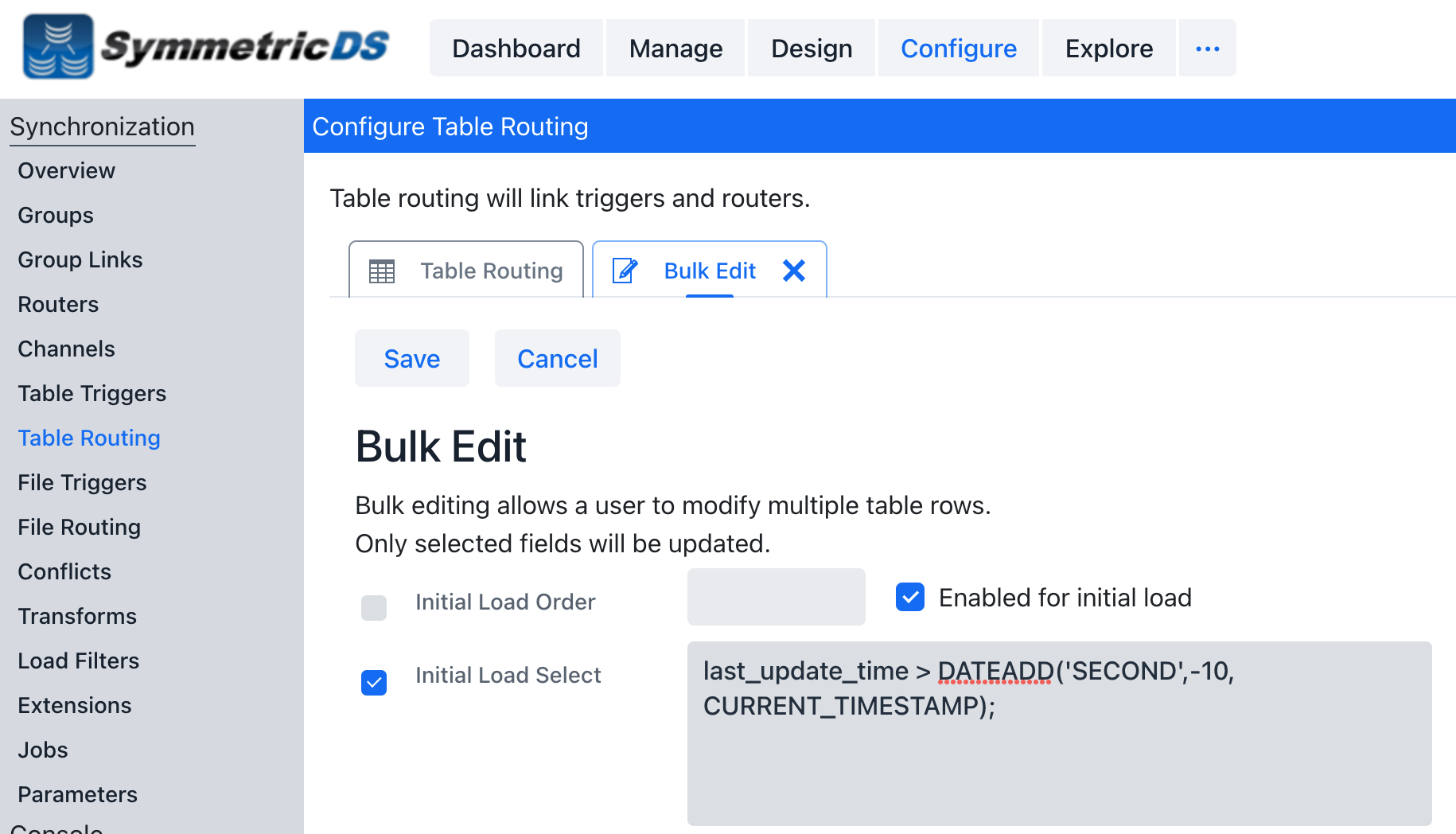
Custom Job
Create a custom job that is configured and scheduled to pull over updates from the source periodically.
TableReloadRequest reloadRequest = new TableReloadRequest();
reloadRequest.setChannelId("time-based");
reloadRequest.setSourceNodeId("YOUR SOURCE NODE ID");
reloadRequest.setTargetNodeId("YOUR TARGET NODE ID");
reloadRequest.setRouterId("ALL");
reloadRequest.setTriggerId("ALL");
reloadRequest.setCreateTime(new Date());
engine.getDataService().insertTableReloadRequest(reloadRequest);




