Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Two days at ExCeL. Hundreds of vendors. Thousands of conversations. And yet, walking away from …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

There are three primary methodologies used in database replication: log based, trigger capture, and time based. Determining which of these approaches is best for your use case can be difficult without understanding the limitations of each type. This article will help identify the differences, pros, and cons of each approach.
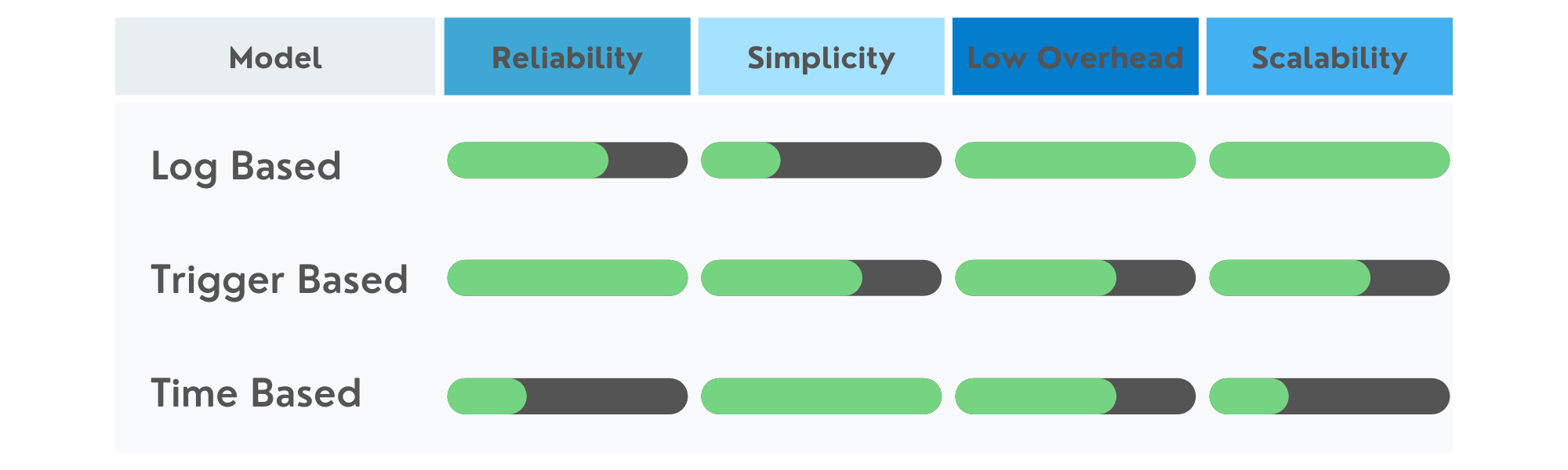
Log based replication is probably the most common and popular approach that many tools support in order to capture changes on a source database. This approach is often viewed as the least invasive approach since the database remains unchanged and only the log files provided by the database are used to determine changes. In general, this is true, however, there is some potential overhead if the database logging must be turned on or set up. Turning on or setting up logging on an active production environment might lead to unexpected changes in performance. If your production database is already configured to enable transaction logging then there would be no additional performance impact on the applications using the database already.
Some other factors should be considered while setting up a log based replication model. The first is the turnover of the log files. Determining how frequently the logs fill up and are removed so that new logs can be created is important to understand. If your log replication tool is not running or is not able to keep up with the load at peak times before logs are rolled over, changes could be lost during these intervals.
Another thing to consider in a log based approach is the number of tables that would contribute to the logging versus how many tables are being configured for replication. For example, if there are 500 tables in the database that are potentially taking on changes but only 10 of these tables need to be replicated, there might be a great deal of overhead in processing the logs for a small set of tables compared to the total set of tables contributing to the logging.
Pros
Cons
Trigger based replication is built on the concept of utilizing database triggers to capture each change as part of the transaction that the change occurs on. Often this is viewed as more invasive than log based because the source tables need to be altered to include the triggers. It is important to understand in this approach a replication tool will be responsible for maintaining these triggers in the event they are not present or the source table is changed.
One of the key values in this approach is that the capturing of a change is directly tied to the user acting on the system. This is because the same transaction that is being used to commit a user change is also ensuring the trigger fires successfully. This ensures all changes are captured or they would roll back with the user change if there was an issue.
Another factor to consider with trigger based solutions is around the data storage of all these changes. Most trigger based approaches will write directly to a set of tables within the database that are created and maintained by the replication tool. As long as the database is sized to scale, these changes will remain present in the database itself and will not have the threat of data loss like the log based approach might have in the event of rolling over the log files.
Pros
Cons
Time based replication consists of selecting changes out of the source directly through queries. Although this requires the least permissions (select access) on the source database, there are some assumptions that need to be qualified in order to work properly. First, there needs to be a column that represents the last time a row was changed (usually a “last updated” column). If there is not a way to construct a query against each table to determine what has changed, this approach will not work properly.
If all the necessary tables for replication provide data within them regarding when they were last modified the next thing to identify is whether or not deletes need to be captured. In most straightforward time based replication, deletes are not supported. The source database would need to perform what is known as “soft deletes” where a deleted column is toggled on or off if the record is to be considered in use. Then the process of updating this soft delete column from a false to true and still utilizing the last updated column the change could be processed through time based replication. Otherwise, a true delete on the source will not be present when selecting changes as the record is no longer present to be retrieved.
Pros
Cons



