Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
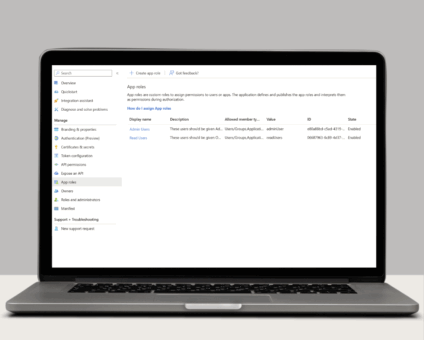
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into a unified analytics platform. SymmetricDS professional edition now supports native integration with Databricks, enabling you to replicate structured data seamlessly from any of the 30+ heterogeneous database platforms SymmetricDS supports directly into your data lakehouse. Whether you’re working with Oracle, SQL Server, PostgreSQL, MySQL, or legacy databases, SymmetricDS provides real-time, data synchronization that keeps your Databricks environment up-to-date with the latest operational data, giving you a truly unified view across your entire data ecosystem.
Setting up SymmetricDS to work with Databricks requires a few configuration steps to ensure performance and compatibility with the Databricks JDBC driver.
The Databricks JDBC driver leverages Apache Arrow for high-performance data transfer. To enable this functionality, Apache Arrow requires access to JDK internals through reflection. This is a one-time configuration that you’ll need to apply to your SymmetricDS installation. Locate the sym_service.conf file in your SymmetricDS conf directory and add the following line:
`wrapper.java.additional=–add-opens=java.base/java.nio=org.apache.arrow.memory.core,ALL-UNNAMED`
This setting exposes the necessary Java internal APIs that Apache Arrow needs to function properly. For additional details about Apache Arrow’s requirements, refer to the official Apache Arrow documentation at https://arrow.apache.org/docs/java/install.html.
When setting up your Databricks target endpoint on the SymmetricDS Canvas interface, navigate to the Custom tab where you’ll find a pre-templated Databricks connection string. You can customize this template by updating the Databricks cloud instance, schema, and HTTP path fields individually, or you can overwrite it entirely with your complete JDBC URL.
For authentication, Databricks typically uses Personal Access Tokens (PAT). When configuring your connection with a PAT, enter “token” in the User ID field, then provide your actual token value in the Password field. This authentication method ensures secure, token-based access to your Databricks workspace.
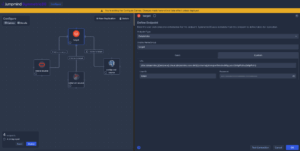
You’ll notice that the Databricks endpoint is configured as a “write-only” capture type. This is by design — SymmetricDS maintains its own metadata and synchronization tables on a separate H2 runtime database rather than creating these tables in your Databricks environment. This architecture keeps your lakehouse clean and optimized for analytics while giving SymmetricDS the operational database it needs for managing the replication process.
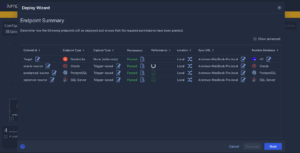
One of SymmetricDS’s most powerful capabilities is its fault-tolerant architecture, which truly shines when dealing with intermittent network connectivity -— a common challenge for organizations with edge devices, remote offices, or distributed operational systems.
When a connection to Databricks is temporarily unavailable, SymmetricDS doesn’t lose data or fail catastrophically. Instead, it intelligently queues changes at the source database and automatically resumes synchronization once connectivity is restored. This queue-and-forward mechanism ensures that every transaction is captured and eventually delivered to your lakehouse, maintaining complete data integrity even through network disruptions.
This capability sets SymmetricDS apart from many cloud-native integration tools that assume constant connectivity and may require complex retry logic or external orchestration to handle outages gracefully. Whether you’re dealing with unreliable network connections at retail locations, manufacturing plants, or field operations, SymmetricDS provides enterprise-grade reliability that keeps your data flowing to Databricks without manual intervention or data loss.
Flexible Data Transformations
SymmetricDS provides powerful transformation capabilities that let you modify, enrich, mask, or filter data during the replication process. You can apply business rules, mask sensitive information for compliance, denormalize data structures for analytics, or filter out unnecessary records, all without building separate ETL pipelines. These transformations happen seamlessly as part of the replication process, reducing latency and infrastructure complexity.
![]()
One of SymmetricDS’s key advantages is its simple, lightweight deployment model. Unlike complex data integration platforms that require extensive infrastructure—separate orchestration layers, message queues, transformation clusters, and monitoring systems—SymmetricDS operates as a self-contained agent that can be deployed directly alongside your databases. This architecture minimizes infrastructure costs, reduces operational complexity, and makes it easy to scale horizontally by simply adding more agents as your data volume grows.
SymmetricDS’s integration with Databricks represents a powerful solution for organizations seeking to modernize their data infrastructure while maintaining reliability, flexibility, and cost efficiency.
The benefits of implementing SymmetricDS for Databricks integration extends across your entire organization with:
SymmetricDS is committed to evolving alongside your business needs. If there’s a feature or capability you’d like to see in SymmetricDS, we encourage you to reach out to our sales team. We actively prioritize customer-requested features and work closely with our clients to ensure the platform meets their unique requirements.
Ready to transform how you move data into Databricks? Contact us today to learn more about how SymmetricDS can streamline your data integration and empower your analytics initiatives.