Shoptalk Europe wrapped up in Barcelona last week and I want to get a few …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Shoptalk Europe wrapped up in Barcelona last week and I want to get a few …

Every retailer we talk to has AI on the agenda right now. Whether it shows …

Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

Everyone is talking about what AI will do for their business. Very few people are …

SymmetricDS Pro 3.17.3 introduces HikariCP as an available connection pool alongside DBCP2 — and the …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

The offering gives security teams a practical path to risk management and accountable AI COLUMBUS …

The insights have implications for retail technology in the store: it must help mind information …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

Data replication is real-time processing and sharing of changes that can improve accessibility, reliability, and fault tolerance. An architecture with real-time information and on-demand processing allows businesses to efficiently manage and access data. Change data capture and data integration enable cross platform synchronization of data across the enterprise, enriching data warehouses, mobile devices, and cloud-based applications. Data replication can help with the following:
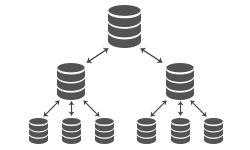
Data from multiple databases are synchronized and combined. This system can scale to thousands of databases arranged into one or more tiers of synchronization. The replication can withstand low-bandwidth connections and periods of network outage. Secure protocols and the use of pull or push synchronization allow replication across firewalls. Conflicts can be handled at the central database or configured to resolve automatically using rules. Remote locations sync with multi-master replication, with some locations receiving shared data or subsets of data.
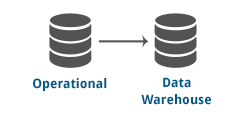
The operational database is replicated to a data warehouse or a reporting database, which can offload work from the main database. The main application continues to use the operational database, while the data warehouse is used for reporting and analysis. Changes made by the application are captured and synchronized with real-time processing, making data available immediately. The data can be filtered, transformed, and supplemented to enhance reporting.
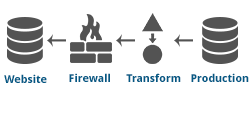
Data is replicated securely from an internal operational database to an external database located behind firewalls or within a DMZ. Data can be transformed during real-time processing to match the structure of the target database. Some reasons to bridge databases are integrating a website database with internal systems, sharing information with another company, or keeping two versions of an application in sync as a migration strategy.
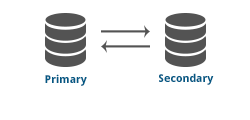
Critical database applications are protected by continuously replicating to a standby database. Changes are sent to the standby, which may be on a local or wide area network. During an outage, the application is reconnected to the standby database. Once the production database is available again, changes replicate to it from the standby. The failover can also be used to perform planned maintenance and system upgrades.
Users can access data from the database that is running and available from the location that is closest to them geographically. Access requests are distributed across multiple databases to balance the load and improve performance. This architecture enables scalability to handle a large number of requests for the database.
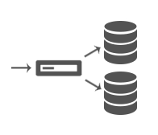
The application uses a local database to access data and make changes, which could be a mobile device on a cellular network or a server connected to a wide area network. Users can work offline during a network outage, and data synchronization keeps the database updated when the network is available again. Conflict management is used to resolve changes in conflict automatically or to request that the user to choose the final change.
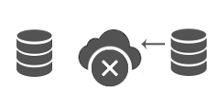
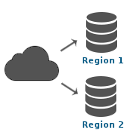
Replicate data to the cloud or across cloud providers and databases. Distribute copies of data changes between regional data centers for local support of applications. Use multiple availability zones and keep databases in sync for high availability. Replicate from on-premise or enterprise databases into the cloud to enable a mobile application. Provision new database instances and add them to replication to scale on demand.