Two days at ExCeL. Hundreds of vendors. Thousands of conversations. And yet, walking away from …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Two days at ExCeL. Hundreds of vendors. Thousands of conversations. And yet, walking away from …

It’s Black Friday morning. Your stores are packed with customers. Credit card in hand, a …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
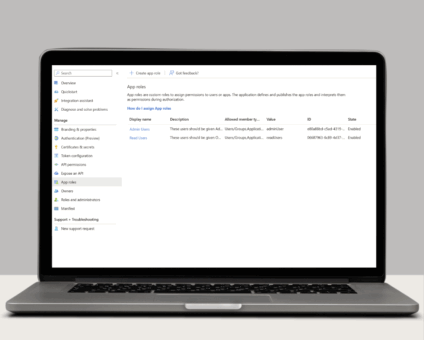
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

The retailer is charting its next chapter with retail technology modernization to power inspired omnichannel …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …
Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

SymmetricDS has been designed around the user upon numerous feature requests from our clients and the open source community. As a result there are a lot of different factors that play a role in how to use it within your project. At a higher level though here are some of the best practices we find should be considered for nearly all implementations.
SymmetricDS performs best when there is a fast and reliable connection between the machine that SymmetricDS runs on and the database. In use cases that involve replicating a few databases located on the same local network a single installation is usually sufficient (multi-homed). However in a wide area network setup it is recommended to install an instance of SymmetricDS near each database.
While SymmetricDS can create tables for you on a target database it is a good practice to review these tables especially when you have different database platforms on the source and target. The DBExport feature can assist in generating a SQL script of the target tables so that it can be reviewed prior to applying to the target system. This allows a user to manipulate any syntax that might not translate from one platform to another. Sometimes there are references to functions or default values that use features only available on the source system.
Jobs are a critical piece to the replication workflow in SymmetricDS and run a schedule that is configurable by the user. The most commonly adjusted job schedules are for the push, pull, routing, and purging jobs. These all have default values but often time people want to know what are the pros and cons around adjusting these values.
Loading data initially is essential to begin the process of change capture to ensure the source and target are in a known state before changes begin to replicate. Below are a few things to consider in order to speed up an initial load.
Groups are the root of all SymmetricDS configuration. All configuration ties up to a group. So setting up your groups up front can take some planning and design but is critical because it could cause rework of your entire configuration if you need to change them. Essentially groups are defined has a piece of shared configuration. You can then have as many nodes (databases) participate in that group as needed and they will all follow the same set of instructions (configuration). So before you start building up a complicated configuration it might be time well spent planning the groups needed to support changes in your configuration. Changes in configuration might be different schemas or table names or the direction the data will be moving. For example you may have designed for one group because the tables are all the same but in reality you may need some tables in database A, B, and C to transform data as well. This would be an example of now using two groups to represent these databases, one with transforms and one without.
By default all change capture goes through the “default” channel and all loading of data goes through the “reload” channel. This may be sufficient for most simple solutions. However groups can be used to increase performance
There can be several root causes for a batch in error but know where to look may help in the debugging process. The first step is to determine the source and target nodes involved in the batch that is in error. This allows you to use the Manage->Outgoing and Manage->Incoming batch screens effectively based on the source or target.
For example, assuming we have groups of server and client and the batch that is in error is moving from the server to the client. We could look at the server’s web console and find the batch on the Manage->Outgoing Batches screen (may need to adjust filters). We could also look at the client’s web console and find the batch on the Manage->Incoming Batches screen if the batch was sent to the client.
We may find different information on each side. If the batch had a problem extracting from the source database we would see more detailed information on the outgoing batches screen. Viewing the batch using the magnifying glass on the outgoing batch screen will allow us to look closer at the batch contents and the errors that were provided. There is a view csv button here that allows us to see the actual contents of the batch that would be transmitted over HTTP/S to the target.
If the outgoing side is not showing enough information we might check the incoming batch details on the other side. Again find the batch on the incoming batch screen a look at the details using the magnifying glass icon.
Common Batch Errors
In summary there are a lot of configurations for the SymmetricDS product to support a variety of use cases. These implementations can also involve a great deal of infrastructure, network resources, and hardware. So these best practices will naturally vary from design to design and are only meant as some starting points and recommendations based on use cases we have experienced in the field.





