Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Two days at ExCeL. Hundreds of vendors. Thousands of conversations. And yet, walking away from …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
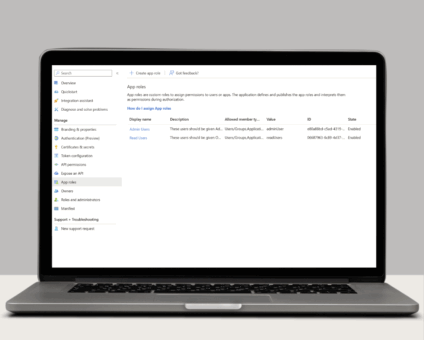
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

Bridge data between databases with data synchronization by using channels to re-order data when the dependencies in each database are different. Each application can model its data differently, so a parent row in one database might map to a child row in another one. Instead of using data transformation to lookup and add dependent data, the order of captured data can be changed to match the constraints of the target database.
Let’s look at two applications that persist customer and address information in their databases. A website database uses the model of “a Customer has an Address”, while a call center application uses “a Premise has a Contact”. We’d like to synchronize the data between the two databases with Customer to Contact and Address to Premise, but the dependencies don’t match on each side. As shown below, you can see the dependency of data is reversed between the two applications. On the website, an Address is created first, followed by a Customer. On the call center, the reverse order must be performed: a Contact is created first, followed by a Premise.
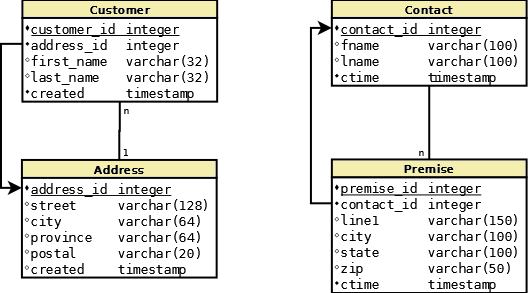
Mapping the tables for data synchronization is difficult when the system loads data the same way it was captured and the database enforces constraints. If Customer is mapped to Contact, and Address is mapped to Premise, the problem is that the data will arrive out of order for the target database. The website will save an Address and a Customer which are sent to call center. When the Address row is mapped and loaded into Premise on the call center, the database will throw a foreign key constraint because the dependent data for Contact hasn’t been loaded yet.
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`callcenter`.`premise`, CONSTRAINT `premise_ibfk_1` FOREIGN KEY (`contact_id`) REFERENCES `contact` (`contact_id`))
We can solve this problem by assigning the tables to channels with different priorities. Channels allow data that would normally be in the same batch together to be split into separate batches and loaded independently. Data is loaded from channels in the order specified by priority, so high priority channels load first. For example, we could create a channel named “parent” with a priority of 10 and a channel named “child” with a priority of 50.
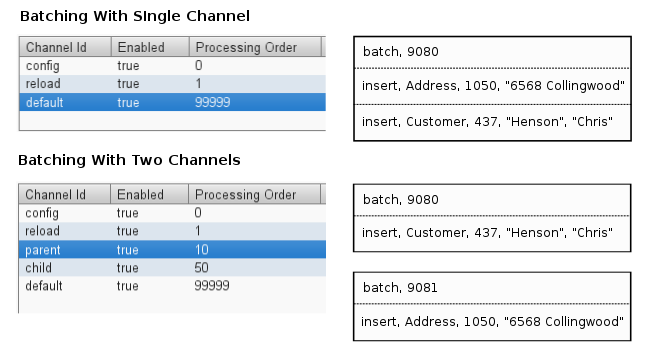
If we assign the Address table to the “child” channel and the Customer table to the “parent” channel, the rows are placed in separate batches, with the Customer data loading first. With the data in the correct order for the target database, now we can map columns and transform data to load Contact and Premise.
SymmetricDS can integrate data between two applications through data synchronization and transformation. We looked at how dependencies like foreign key constraints can make it challenging to map tables and columns between different databases. Channels provide a way to separate transactional data into batches that can be ordered and loaded independently, making the next step of transformation easier.




