Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

The last thing a piece of software wants to be called is a “monolith“. “Monolithic” sounds a bit too much like “paleolithic” – evoking images of a prehistoric and unwieldy system. Then there’s the concept of “microservices” which promise scalability and success – even at Netflix scale. There are lots of articles on the monolith vs. the microservice, but here I want to consider these paradigms in the context of enterprise point of sale and our new product, Jumpmind Commerce, specifically. Read on to learn how we leverage microservices even while supporting robust offline functionality.
The choice between a monolithic vs. microservice-based architecture has implications for your development team, release schedule, development costs, and much more.
In a nutshell, a monolith is an application where all the business logic and data access (and potentially UI) are rolled up into one bundle of an application. One big team tends to work on it.
On the other hand, instead of being one large app, a microservice-based application distributes logic, often by business domain, across multiple, independent services, each with its own data store.
Here is a simple comparison of the same app in the monolith vs. microservice style:
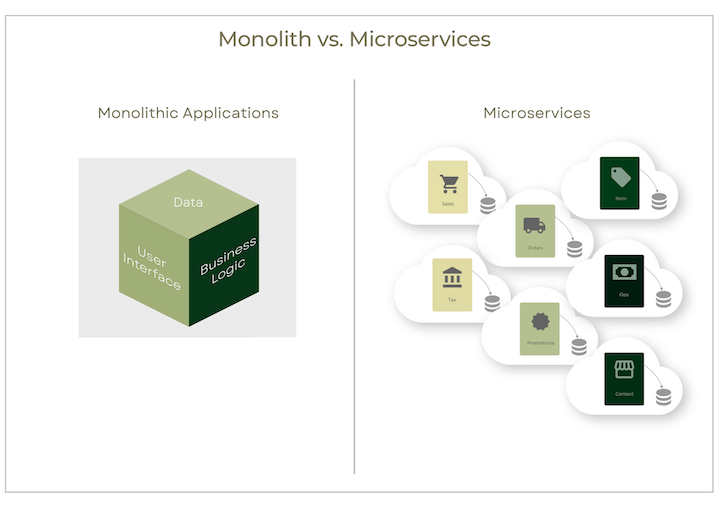
Here’s a quick comparison of how monolith and microservice approach certain topics:
|
Monolith |
Microservice |
|
|---|---|---|
|
Scaling |
Entire application scales as a unit |
Individual services can scale vertically or horizontally, as usage dictates |
|
Dev Team |
Requires broad expertise to comprehend the breadth of the system |
Smaller teams can focus on one, simpler service area |
|
Releases |
Less frequent and higher risk because the whole application is released as one unit |
Individual services can be released more frequently. CI/CD is more manageable with smaller units |
|
Complexity |
A monolithic is simpler and more rapid to develop for smaller systems |
Large, complex systems benefit from microservice architecture because the complexity is cleanly divided by service |
|
Tech Stack |
Tends to be a single tech stack on one VM to run the application |
With microservices – since each area of business functionality lives behind an API – different tech stacks can be used where it makes sense |
|
Database |
Usually one big relational DB |
At least one DB per service, more flexibility to use a variety of database types |
|
Purity of Boundaries |
The boundaries between business domains (e.g. Customer vs. Order in an e-commerce system) will blur over time |
Microservices enforce separations between business domains |
|
Runs on |
1 machine |
Multiple VMs |
The promises of microservices are most welcome in point-of-sale: rapid deployments, scaling only what needs to be scaled (e.g. giving more processing power to promotion calculation), horizontal database scaling – just to name a few. You can picture how this would be accomplished on the backend, services side:
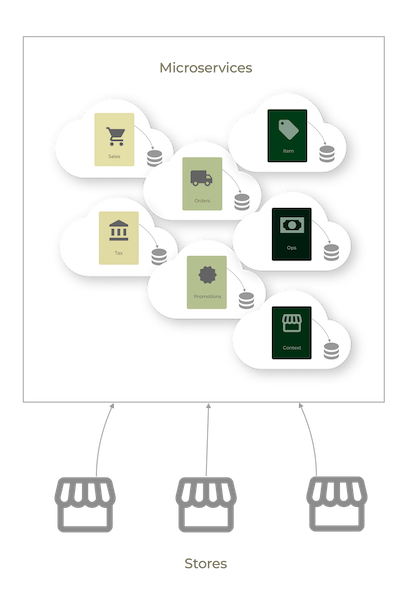
So far so good, but point-of-sale is a mission-critical, in-store application that often needs to run offline.
Some vendors punt, offering significantly reduced functionality when running offline. With that approach, you have your microservices access when running normally/online, but fall back to simplified functionality in a small monolith application that runs in the store. I see several issues with that. Most obviously, it would be ideal to have roughly the same functionality whether online or offline (think complex tax calculations, promotions, etc.) Also, there is duplicated effort to build the true functionality into the microservice, and then the diminished functionality into the offline app, and as soon as there is business logic duplication – there is increased testing time and more bugs.
When we laid the groundwork for Jumpmind Commerce, a microservice architecture was a priority. Some services like promotion or tax are prime to be shared between ecommerce and store systems, and have different scaling profiles from other services like customer lookup.
But the question remained of how to handle offline situations. That is, when Jumpmind Commerce is offline from the central microservices and has to run in a local, self-contained mode, how is that accomplished?
For this, we opted to take a “pragmatic approach” to our microservices, meaning that the services are designed to run independently as pure microservices OR in the same VM, with any combination possible. This allows the microservices to be bundled together and formed into an application to run on an individual cash register instance.
You could call this a hybrid approach to microservices, and for POS I would argue it’s ideal if you need to enjoy the benefits of microservice architecture in the cloud and at the same time support full offline functionality in the stores. To accomplish this, our microservices adhere to the following principles:
Jumpmind Commerce has sophisticated orchestration logic built-in to support this model of hybrid microservices:
One last comment on the advantage of microservices in enterprise point of sale. I have worked on several large-scale monolithic applications in my career, and while they were all high-quality, inevitably the business logic domains do bleed together over time. Worse, business logic blends with application flow logic, and even UI logic in a monolith. So when the time comes to reuse that business logic in another context, it’s just not possible because it’s so embedded within the assumptions of the original application (think one line of code calculating a total, the next line of code requesting to advance the screen, etc.)
One key advantage of the Jumpmind architecture is that microservices are purely devoted to business logic, without the chance of being contaminated by other services, application flow, or UI concerns. Having your business logic clearly and cleanly expressed this way opens a world of possibilities for the omni experiences shoppers expect in a post-COVID world.