Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Imagine this: your POS vendor only supports Windows, but your store associates prefer iPads, your …

Your POS system shouldn’t be an island. In today’s retail environment, your point-of-sale platform needs …

Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
Introduction In retail, POS updates have traditionally been quarterly events at best. From October through …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

LONDON – April 21, 2026 – Jumpmind, a leading provider of innovative retail technology solutions, …

Physical retail in Europe is in a stronger position than many headlines suggest. New research …
If you run SymmetricDS in production, you know the drill: dozens of nodes, constant data …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
A comprehensive solution designed to simplify and give you ownership of the inventory lifecycle.
![]()
A native post-transaction reconciliation module built into Jumpmind Commerce.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.

Subsetting data during replication can improve the overall performance of your sync scenario and reduce the size of target databases. This article will explain some of the ways SymmetricDS will allow you to subset your data and how to consider the performance implications with each case.
A common replication use case involves a centralized database that is synchronizing multiple client (remote) databases. A simple configuration would be to just send all the data to all locations. However there are often tables that do not need to be fully sent to each client node. This is when subsetting should be considered to avoid cluttering your network and client databases with unnecessary data that is not used.
Subsetting is the process to make decisions at the central node regarding which data should be sent to each client.
In general subsetting can be best accomplished in SymmetricDS through a variety of routers. Routing in SymmetricDS is the process by which changes are assigned batches and target nodes so that they can be replicated. There are 3 out of the box routers (a fourth coming in 3.11) that will likely cover all your subsetting needs and will be discussed with the pro’s and con’s of each below as well as a few alternatives.
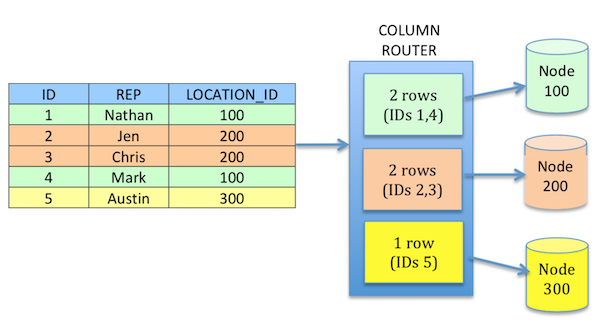
Column match routers are the fastest and and simplest subsetting router to configure. They simply require a column on the table being replicated that will contain the value of the node ID each row is to be sent. This router can also be reused for all tables that utilize the same column name for subsetting.
For example if you have 10 tables that each have a LOCATION_ID column, a column match router (router expression LOCATION_ID=:NODE_ID) can be used to replicate all of these tables. This will result in only rows that match a registered node ID being sent to the appropriate client.
Pros
Cons
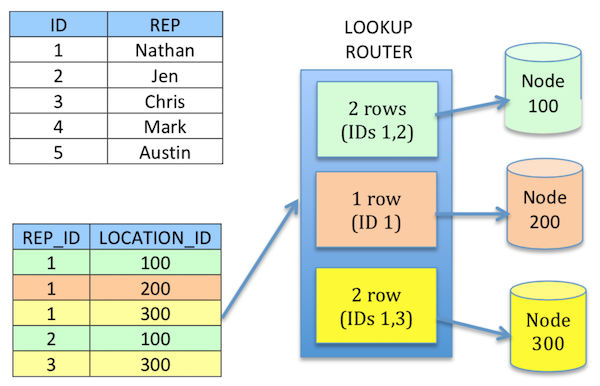
Lookup table routers use a dependency or relationship table to look up the target node’s external id. This allows a single row to have multiple targets if there are multiple matching rows in the lookup table. This does involve some additional database work because the necessary information used during routing must be queried from an additional table. In order to improve performance though the full lookup table is loaded into memory each time the routing job runs. This can eliminate more than one call to the database to lookup all data using this router. However since the table is loaded into memory it is not a great fit for large lookup tables (millions of rows).
Pros
Cons
NOTE in the example below the REP with ID of 1 is sent to all 3 target nodes based on the rules in the lookup table.
Sometimes the subsetting logic is more complicated than a single column or a single lookup table. As a result more advanced queries are needed to determine where a row of data should be sent. In these cases a subselect router might be an option. Be cautious while configuring a subselect router though as every row change that occurs will initiate an additional subselect database query to be ran to determine the target node(s). This might not be of much impact if the number of changes are trickling in and your systems are designed to handle the additional load. However with transactions that create a large number of changes on a single table that is configured for subselecting this could slow down the replication time of changes arriving at their destination (see convert to reload router below).
Pros
Cons
If the routers above are unable to meet your business case for subsetting there are more custom approaches that can be used. The scope of these will not be addressed in this blog article but more details are available in the documentation. In short these options allow for users to provide a programmatic approach to routing through various coding languages.
As a solution to the overhead that is caused using a subselect a new approach was designed in 3.11. The new convert to reload router supports use cases where a subselect is required (multiple tables involved in subsetting) and there are many changes coming in at once. This might happen with an overnight batch process that loads in a great deal of changes in a single run that all require complex logic in order to subset.
The convert to reload will capture the primary keys of these changes only and load them into a temp table. The subselect query can then be provided to run a single time to join the temp table to the necessary business tables so that all the data can assigned an appropriate target node with a single query instead of one per row. This will then generate a reload event for each of these rows in SymmetricDS to sync only the changes.
Pros
Cons




