COLUMBUS, Ohio – November 5, 2025 – 54% of North American retailers surveyed say they …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
COLUMBUS, Ohio – November 5, 2025 – 54% of North American retailers surveyed say they …

36% of retailers say meeting the demands of hyper-informed customers is one of the top …

Physical retail is still where the magic happens. According to new research by RSR, 85% …
Overview Organizations today face the challenge of consolidating data from on-premise and cloud-based systems into …
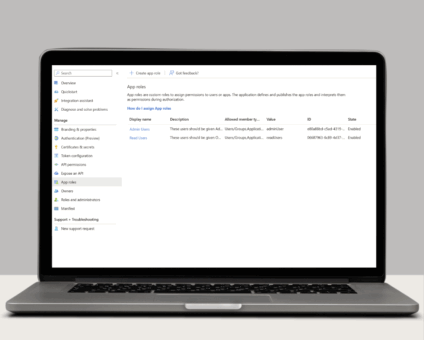
Single Sign-On with OAuth 2.0/OpenID Connect One of the many new features included in version …
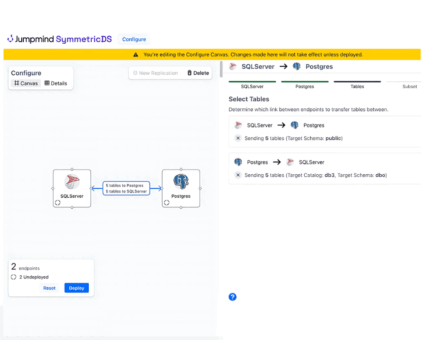
The new release of SymmetricDS Pro 3.16 data replication software simplifies setup, improves performance, and …

Jumpmind Powers Point of Sale and Promotions Execution for Landmark Retail, One of the Largest …

Retail Technology Leader Jumpmind to Enable Mobile Point of Sale and Inventory Management for DTLR/VILLA …

The retailer is charting its next chapter with retail technology modernization to power inspired omnichannel …

Jumpmind Appoints Technology Veteran Mike Webster to Board of Directors Jumpmind recently welcomed Mike Webster …

The partnership will drive innovation, expand global reach, and reinforce Jumpmind’s position as a leader …

After nearly a century in business, the legendary Canadian fashion retailer is retooling to streamline …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Explore our thinking and see how our expertise can become your advantage.
Clienteling isn’t a new theory. It can be traced back hundreds of years when shopkeepers took detailed records of each customer to provide better service the following visit. While many of today’s clienteling solutions drive engagements that feel more complex …