Retailers are constantly looking for new ways to generate revenue and stay competitive. One strategy …

![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Retailers are constantly looking for new ways to generate revenue and stay competitive. One strategy …

Clienteling isn’t a new theory. It can be traced back hundreds of years when shopkeepers …

BOPIS, BORIS, and Curbside Pickup offer consumers and retailers the best of both worlds. …
The SymmetricDS product can synchronize data between over forty different database platforms with out of …

Compare and Repair for SymmetricDS Pro can compare two databases, report on the differences, and …
Mobile replication with Android edge devices in near real time to an on-premise or cloud …

Jumpmind President and CEO Joe Corbin to Lead Panel on Agility at Scale and Digitalizing …

Retail Technology Leader Jumpmind Brings Newfound Interactive and Personalized Digital Engagement to Inspire Shoppers at …

Retail Technology Leader Jumpmind Provides Enhanced Experiential Point of Sale and In-Store Engagement for Build-A-Bear Workshop …
![]()
Cloud-native POS platform for seamless omnichannel customer experience.
![]()
A single hub for all promotions campaigns.
![]()
The most advanced synchronization solution for databases and file systems.
![]()
Data configuration and batch automation across different disparate systems and vendors.
Often when setting up data replication it is necessary to redirect or transform the source tables and columns into a different set of target tables and columns. SymmetricDS offers this transformation feature as part of the real time data replication workflow. Below we will review the places within the workflow this transformation can take place and how to configure it.
Many ETL based tools on the market are great a providing a solution around data manipulation and transformation as part of a scheduled process. However if you need to perform near real time transformations on changes as they occur SymmetricDS can be a powerful asset to continuously perform these transformations as part of the replication process without any additional nightly schedule of batch jobs.
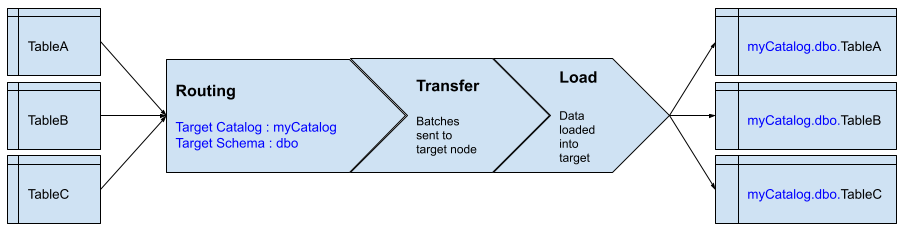
First we need to understand the components that make up the replication pipeline and when they are executed. The image below diagrams all the components that can be potentially used as part of the replication pipeline. In order for these to execute properly though the catalog, schema, and table information configured must match as the batch works through the pipeline. If any of these configuration values (catalog, schema, table) do not line up with the step prior the transforms or filters will not execute.

Routing is the process that checks for newly captured changes and will determine where they need to go by assigning them to a batch. Target catalog, schema, and table information can be set at the router level. This is often the simplest way to change the target information for multiple tables. Setting the target catalog and schema at the router will effect all tables that flow through this router (table routing) and allows a single configuration point.
TIP: Setting target information on the router works well when you just need to change the catalog and/or schema but not the table names. If you need to also transform table names it is better done through transforms.
These transforms fire on the source if the source catalog, schema, and table match the values that came out of routing. There are 3 ways to hook up an extract transform.
![]()
![]()
![]()
These transforms fire on the target side if there is a match. There are 2 ways to hook up a load transform
![]()
Load filters must provide a target catalog, schema, and table combination that matches the upstream settings in the pipeline in order to execute. Load filters can provide a variety of customizations on the data once executed. Below is an example of how you could set the target catalog and schema on the target side rather than through a router or transforms. This might be useful if only the target knows where their data should be loaded into (remember routing occurs on the source). Through the use of a wildcard (*) as the target table a single load filter can support all tables rather than setting up a transform for each table.

Example: Beanshell load filter “Before Write” to set the catalog and schema.
// Check that the table is not a SYM_* runtime table
if (!table.getName().startsWith(engine.getTablePrefix())) { table.setCatalog("catalog1");
table.setSchema("dbo");
}
return true;
Example : Similar to one above but the values now are dynamic and could be set in each targets engine properties file (target.catalog and target.schema).
// Check that the table is not a SYM_* runtime tableengine.getParameterService().getString("target.catalog")
if (!table.getName().startsWith(engine.getTablePrefix())) { table.setCatalog();engine.getParameterService().getString("target.schema")
table.setSchema();
}
return true;





